weekend paper reading: w46
I lied this was done on monday. very incomplete.
==================================
trying something out
- first i read all the papers in the list, get their ideas, note it down
- then i use a lite version of this framework to think more critically about each paper (summarize -> strengths -> weaknesses -> improvements/questions)
i've been thinking about how to be more critical reading papers and not be like this. this comment really stuck with me:
This reviewer doesn't understand at all that a research paper only needs to clearly present and justify its main contribution, but instead asks for a product development report where every microscopic detail must be thoroughly studied.
my current understanding is that a paper needs to 1) present its points and 2) justify it sufficiently. criticism should be focused on
- quality of idea and methodology
- whether the idea is sufficiently justified with the evidence provided
- how it compares to previous works (and whether it overlooks any)
pretraining large language models in nvfp4
https://arxiv.org/pdf/2509.25149
notes
smaller number = faster computation mixing precisions, numerically sensitive layer kept in high precisino improved quantization scheme using
- block quantization
- values are scaled in blocks instead of individually
- preserves consistency across transformations in forward and backward
- scale is shared within the block
- with 1D scaling you're doing max(row) / num_vals, so the scale is different for forward and backwards
- with 2D you're using a whole block so it's the same even after transposition
- less granular but just let the weights adapt
- random hadamard transforms
- this means using random hadamard matrices to limit outliers
- hadamard matrices are orthogonal matrices with values limited to ±1
- H_d = (1/√2) H_2 ⊗ H_{d/2}
- redistributes weights, but preserves energy
- deterministic because of seed
- orthogonal means they cancel out
takeaways
- so this paper shows that that it's possible to achieve near equal performance to fp8 with nvfp4
- nvfp4 ~matches fp8 in perf on a 12B model with 10T tokens
- matches fp8 entirely if you keep the last 20% of training in bf16/fp8
- mixed precision is good, keeping the final few layers in bf16 shows better perf
- combined
- nvfp4
- hadamard random transform
- 2d block scaling
- mixed precision
nvfp4 format
- block size 16 elements
- E4M3 format instead of UE8M0, greater range of expression
what is a block
- fp32 mapped into representable range of a block
- per block e4m3 scale moves value into block
Virtual Width Networks
https://arxiv.org/pdf/2511.11238
wider embedding -> send 2/3 of that into the transformer, remaining third is used as weighted rescons
notes
- decouples representational width from backbone width (?)
- big embedding space
- reportedly scales well (2x for NTP and 3x for N2TP)
- more compression?
- yeah the embedding is compressed before being passed into the transformer
- bigger embedding, replace residual connection with hyperconnections
- bigger embedding - more representations
- hyperconnections?
- residual connections with weights basically. skimmed https://arxiv.org/pdf/2409.19606 in like a minute but yeah
- they route the connection matrices based on the inputs
contributions
- vwn
- generalized hyperconnections
- demonstrates that this works with MTP
MarsRL: Advancing Multi-Agent Reasoning System via Reinforcement Learning with Agentic Pipeline Parallelism
https://arxiv.org/pdf/2511.11373
pipeline for multi agent reasoning system
notes
- read gemini imo gold paper for source
- prev. solver-verifier-corrector pipeline:
- each agent is given a single purpose
- solver solves the problem
- verifier detects error
- corrector fixes accordingly
- this technique didn't work with OSS models as well
- much RL is tool-integrated reasoning
- issues with current RL
- rewards are shared
- issues with current RL

marsRL
VC RL works great, but apparently only for Gemini 2.5 Pro.
- rewards are assigned to agents individually, credit roles are decoupled
- solver and corrector gets rewarded based on their solutions and ground truth
- verifier gets rewarded based on the correctness of its classification; if correct answer + incorrect verifier -> verifier gets penalized
- ain't this very similar to a GAN
- pipeline parallel on an agent level?
- i assume this is t1(agent1_{task1}) t2(agent1_{task2} agent2_{task1}) etc etc
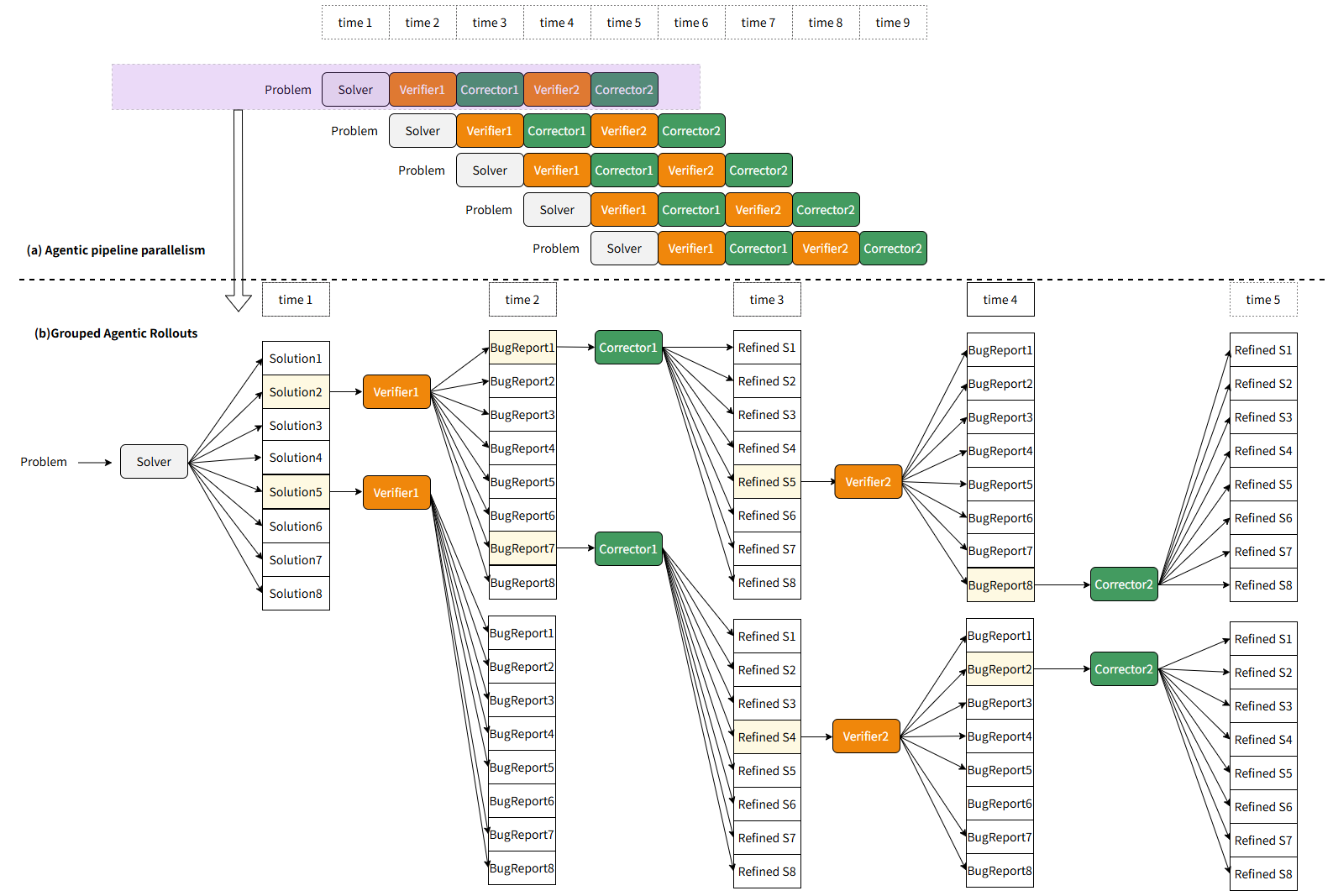
- i assume this is t1(agent1_{task1}) t2(agent1_{task2} agent2_{task1}) etc etc

perf wise this improves qwen3 a3b thinking 2507 by 5% at least across the board, which is quite good. i'd like to see bigger models benchmarked with this though.
thoughts
- how does one engineer a system/framework for multi-agent RL for this
- https://github.com/TsinghuaC3I/MARTI
- https://github.com/PRIME-RL/TTRL
- hmm this is tree search basically
- not quite monte carlo?
- naturally one would wanna restrict the search space
- intelligent way of doing it?
- would be good for flexible workloads
- hmm
- can you use similar pipelines to improve codegen or whatever?
- normal interactions, use it
- takes the user-agent interactions, then another model looks at that to identify what the model should have done for a better trace
- finetune using trace
Winning Gold at IMO 2025 with a Model-Agnostic Verification-and-Refinement Pipeline
https://arxiv.org/pdf/2507.15855
half of this paper was prompt lol
most of it was covered in the prev. paper, but it demonstrated that this technique worked to get gold. nice.
Photon: Federated LLM Pre-Training
https://arxiv.org/pdf/2411.02908
cross silo FL for global scale training
- small batch size + high LR
- async trianing
- 20% higher throughput compared to centralized distributed training? what? what centralized? how centralized? how are the GPUs linked together?
basics
- federated learning benefits
- data locality
- distributed gpus
thoughts
- woah distributed global serverless cluster